Transformer From Scratch
Implementasi arsitektur Transformer from scratch berserta dengan penerapan konsep matematika menggunakan numpy.
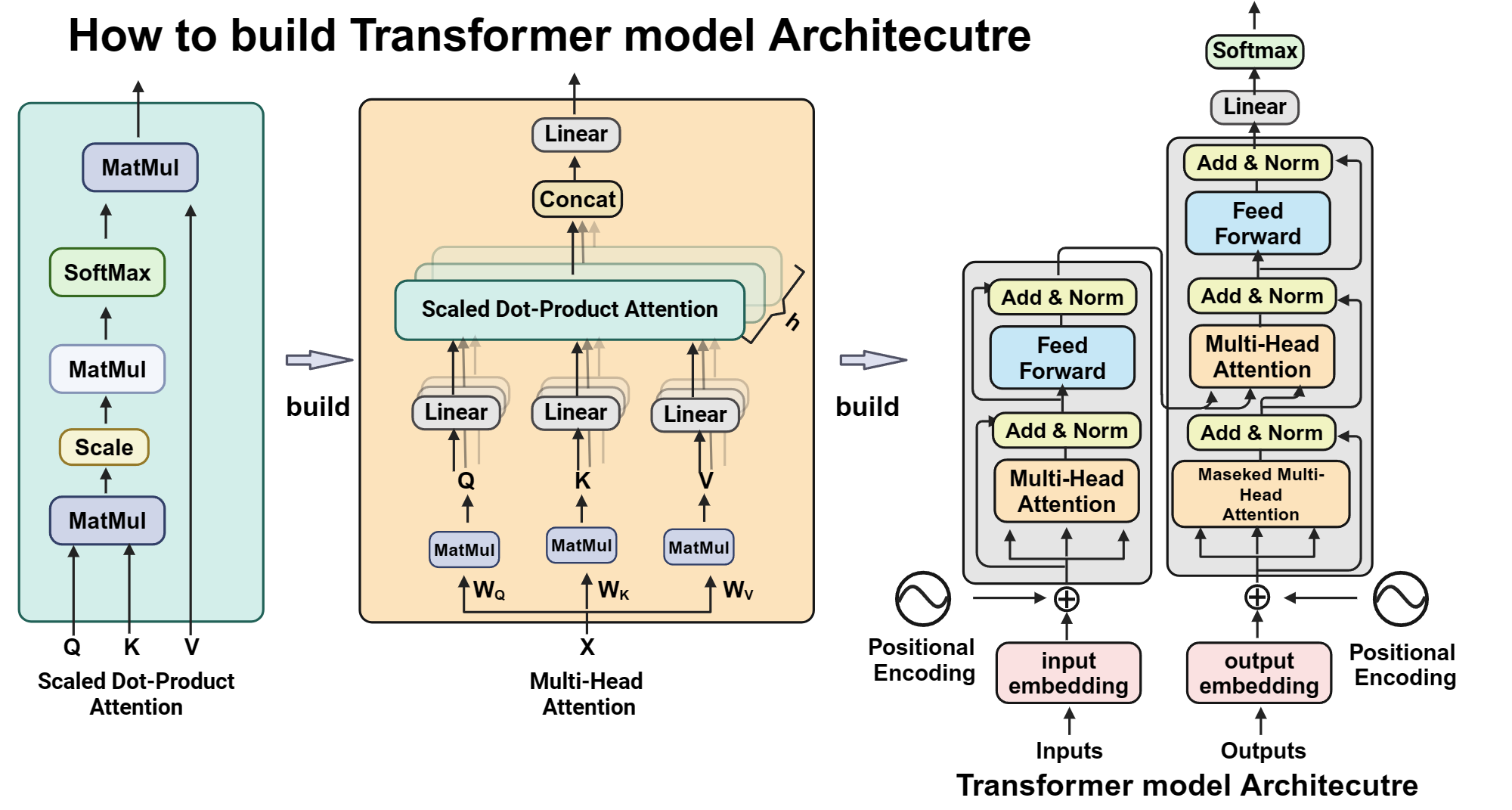
Transformer From Scratch
Project ini adalah implementasi arsitektur Transformer dari nol hanya menggunakan NumPy dan konsep matematika yang saya pelajari.
Project ini merupakan bagian terakhir dari rangkaian eksplorasi saya dalam memahami berbagai arsitektur deep learning secara mendalam.
Sebelumnya saya telah mengimplementasikan beberapa arsitektur neural network dari nol seperti ANN, CNN, RNN, dan LSTM. Pada project sebelumnya saya menggunakan arsitektur LSTM untuk membuat model sederhana yang dapat memprediksi kata selanjutnya dalam sebuah kalimat.
Namun ketika mencoba memproses kalimat yang lebih panjang, saya menyadari adanya keterbatasan dari pendekatan berbasis recurrent seperti LSTM.
Problem
Pada arsitektur seperti RNN dan LSTM, proses komputasi dilakukan secara sequential, artinya setiap kata harus diproses satu per satu berdasarkan urutan waktunya.
Sebagai contoh:
- model harus memproses kata pertama terlebih dahulu
- kemudian kata kedua
- lalu kata ketiga
- dan seterusnya
Pendekatan ini membuat proses komputasi menjadi sulit untuk diparalelkan.
Padahal perangkat keras modern seperti GPU dirancang untuk melakukan komputasi secara parallel dalam jumlah besar.
Akibatnya, ketika kita memproses sequence yang panjang, model berbasis recurrent seperti LSTM menjadi kurang efisien dan relatif lebih lambat.
Solution
Untuk mengatasi keterbatasan tersebut, para peneliti memperkenalkan arsitektur Transformer.
Alih-alih memproses kata satu per satu secara berurutan, Transformer menggunakan mekanisme yang disebut self-attention.
Dengan mekanisme ini, setiap kata dalam sebuah kalimat dapat memperhatikan (attend) semua kata lainnya dalam sequence secara langsung.
Artinya:
- semua kata dapat diproses secara bersamaan
- hubungan antar kata dapat dihitung secara parallel
- proses training dan inference menjadi jauh lebih efisien
Pendekatan ini sangat cocok dengan kemampuan komputasi GPU modern.
Karena keunggulan tersebut, Transformer kemudian menjadi fondasi utama bagi banyak Large Language Model modern.
Self-Attention Mechanism
Konsep utama dalam Transformer adalah self-attention.
Self-attention memungkinkan model untuk menghitung seberapa penting sebuah kata terhadap kata lainnya dalam sebuah kalimat.
Sebagai contoh dalam kalimat:
"Saya makan nasi dengan ayam tadi sore"
Model dapat belajar bahwa beberapa kata memiliki hubungan yang lebih kuat dibandingkan yang lain.
Melalui mekanisme attention, model dapat memahami konteks kalimat secara lebih fleksibel tanpa harus bergantung pada urutan pemrosesan yang sequential seperti pada RNN atau LSTM.
Transformer Architecture
Secara umum, arsitektur Transformer terdiri dari dua bagian utama:
Encoder
Bagian encoder biasanya digunakan untuk memahami representasi dari sebuah input sequence.
Encoder banyak digunakan pada model yang fokus pada tugas seperti:
- klasifikasi teks
- sentiment analysis
- question answering
Decoder
Decoder biasanya digunakan untuk menghasilkan sequence baru berdasarkan konteks sebelumnya.
Arsitektur ini digunakan pada tugas seperti:
- text generation
- machine translation
- language modeling
Implementation
Dalam project ini saya hanya mengimplementasikan decoder block dari Transformer.
Hal ini karena tujuan utama saya adalah membuat model yang dapat memprediksi kata berikutnya dalam sebuah sequence, mirip dengan cara kerja model language modeling.
Sebagai tambahan, banyak model language model modern seperti GPT juga menggunakan pendekatan decoder-only architecture.
Dalam implementasi ini saya membangun beberapa komponen utama Transformer secara manual menggunakan NumPy, seperti:
- self-attention mechanism
- attention score calculation
- projection matrices
- feed forward layer
- forward propagation
Seperti project deep learning sebelumnya, saya juga menggunakan pendekatan Object Oriented Programming (OOP) agar struktur kode lebih modular dan mudah dikembangkan.
Tech Stack
Project ini dibangun menggunakan teknologi berikut:
- Python
- NumPy
- Deep Learning fundamentals
- Transformer architecture
Learning Outcome
Melalui project ini saya dapat memahami bagaimana arsitektur Transformer bekerja sebagai dasar dari banyak Large Language Model modern.
Saya juga memahami bagaimana mekanisme self-attention memungkinkan model untuk memproses sequence secara parallel, yang membuat Transformer jauh lebih efisien dibandingkan arsitektur recurrent seperti RNN atau LSTM.
Project ini menjadi penutup dari rangkaian eksplorasi saya dalam mempelajari berbagai arsitektur deep learning dari level fundamental hingga konsep yang digunakan dalam sistem AI modern.