Transformer
Penjelasan arsitektur transformer.
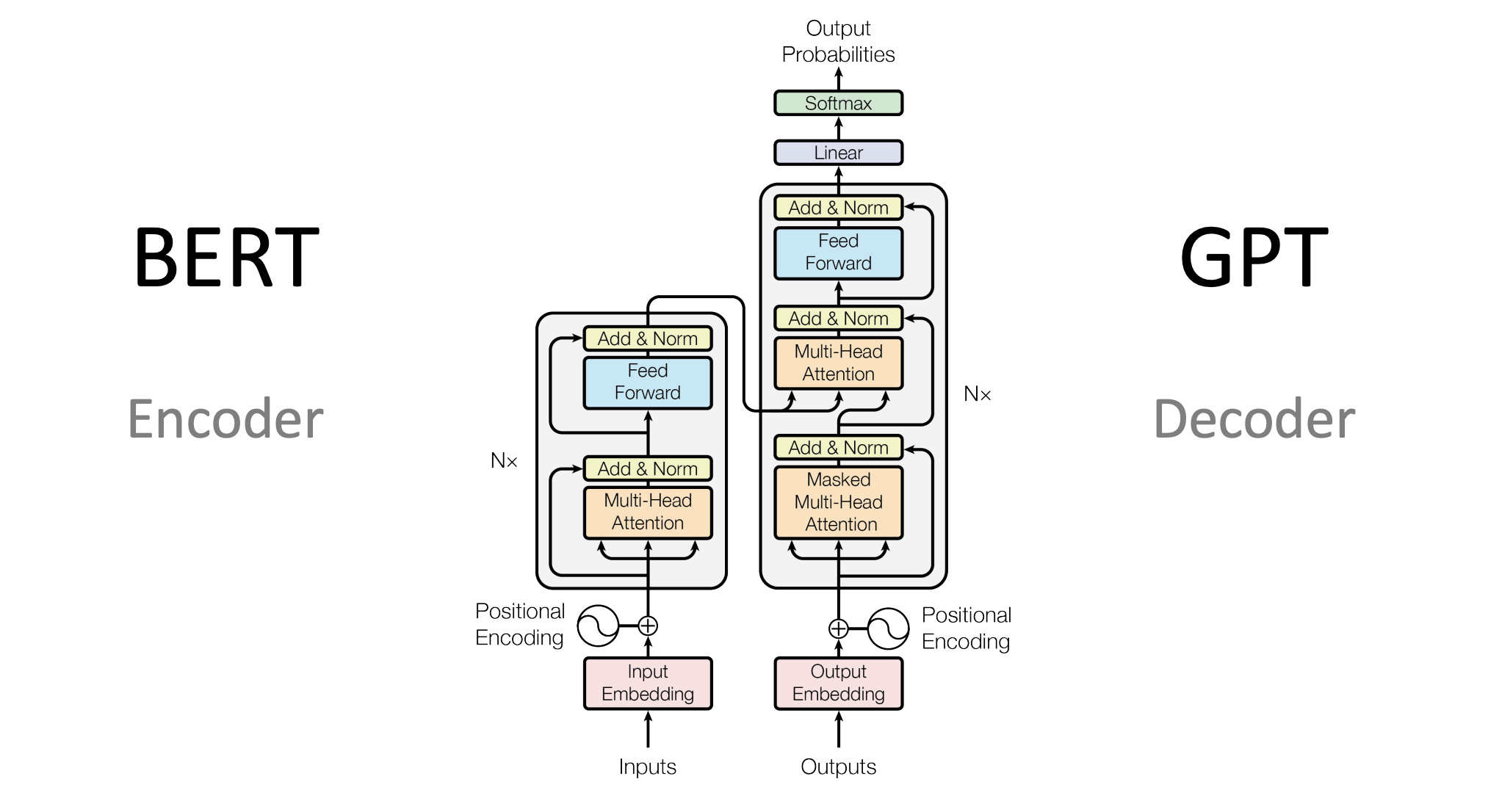
Transformer Architecture: Dari Sequential ke Parallel Thinking
Transformer adalah salah satu arsitektur yang sangat penting dalam perkembangan AI saat ini. Arsitektur ini diperkenalkan oleh peneliti Google pada tahun 2017 melalui paper yang berjudul Attention is All You Need.
Transformer dibuat untuk menyelesaikan permasalahan yang ada pada arsitektur sebelumnya, yaitu Recurrent Neural Network (RNN) dan turunannya seperti LSTM dan GRU.
Pada mekanisme recurrent, proses training dilakukan secara sequential, artinya model harus memproses token satu per satu sesuai urutan. Hal ini membuat proses training menjadi lambat dan kurang efisien, terutama ketika berhadapan dengan sequence yang panjang. Selain itu, mekanisme ini juga sulit untuk diparalelkan pada GPU yang sebenarnya didesain untuk komputasi parallel.
Dari situlah muncul ide sederhana namun powerful: bagaimana jika semua token bisa diproses secara bersamaan, dan masing-masing token dapat “memperhatikan” token lainnya?
Transformer menjawab pertanyaan tersebut dengan mekanisme yang disebut self-attention.
Dengan self-attention, setiap token dalam sebuah sequence dapat melihat dan mempertimbangkan token lainnya secara langsung. Hal ini memungkinkan proses komputasi dilakukan secara parallel, sehingga jauh lebih efisien dibandingkan dengan arsitektur sebelumnya.
Pada tulisan ini saya akan membahas bagian-bagian utama dari arsitektur Transformer berdasarkan paper Attention is All You Need, dengan fokus pada konsep matematikanya. Untuk implementasi kodenya sendiri sudah saya tulis pada halaman project di web ini.
Arsitektur Umum Transformer
Secara umum, Transformer terdiri dari dua block utama:
- Encoder
- Decoder
Masing-masing block memiliki fungsi yang berbeda.
Encoder bertugas untuk memahami input sequence dan menghasilkan representasi (embedding) yang kaya akan konteks. Biasanya digunakan untuk task seperti klasifikasi teks.
Sedangkan decoder bertugas untuk menghasilkan output sequence, biasanya digunakan untuk task generatif seperti prediksi kata selanjutnya.
Beberapa model menggunakan hanya encoder (seperti BERT), hanya decoder (seperti GPT), atau kombinasi keduanya (seperti Transformer original untuk translation).
Komponen Utama dalam Transformer
Setiap block dalam Transformer (baik encoder maupun decoder) terdiri dari beberapa komponen utama:
- Positional Encoding
- Multi-Head Attention
- Feed Forward Network
- Residual Connection & Layer Normalization
Pada decoder terdapat tambahan mekanisme yaitu masked multi-head attention.
1. Positional Encoding
Berbeda dengan RNN, Transformer tidak memiliki konsep urutan secara natural karena semua token diproses secara parallel.
Oleh karena itu, kita perlu menambahkan informasi posisi ke dalam setiap token. Di sinilah peran positional encoding.
Positional encoding biasanya menggunakan fungsi sinus dan cosinus untuk merepresentasikan posisi token dalam sequence. Dengan cara ini, model dapat mengetahui urutan token tanpa harus memprosesnya secara sequential.
Secara sederhana, positional encoding membantu model menjawab pertanyaan:
“Token ini berada di posisi ke berapa dalam kalimat?”
Untuk matematikanya biasanya saya menggunakan sinus sebagai positional encoding setiap token dengan rumus:
Dimana:
- pos adalah posisi token dalam sequence (0, 1, 2, ...)
- i adalah index dimensi dari embedding
- d_model adalah ukuran dimensi embedding (misalnya 512)
Secara intuitif, fungsi sinus dan cosinus ini bekerja seperti "gelombang" dengan frekuensi yang berbeda-beda untuk setiap dimensi embedding.
Hal ini memungkinkan model untuk:
- Menangkap informasi posisi absolut (posisi ke-n)
- Sekaligus memahami relasi posisi relatif antar token
Menariknya, dengan pendekatan ini model juga bisa melakukan generalisasi ke sequence yang lebih panjang dari yang pernah dilihat saat training, karena pola sinus dan cosinus ini bersifat kontinu dan tidak terbatas panjang sequence.
2. Multi-Head Attention
Ini adalah bagian paling inti dari Transformer.
Self-attention bekerja dengan tiga komponen utama:
- Query (Q)
- Key (K)
- Value (V)
Setiap token akan diubah menjadi Q, K, dan V melalui proses linear transformation.
Kemudian dilakukan perhitungan:
Dari rumus tersebut, model akan menghitung seberapa besar perhatian (attention) suatu token terhadap token lainnya.
Namun dalam Transformer, tidak hanya satu attention yang digunakan, melainkan beberapa attention sekaligus, yang disebut sebagai multi-head attention.
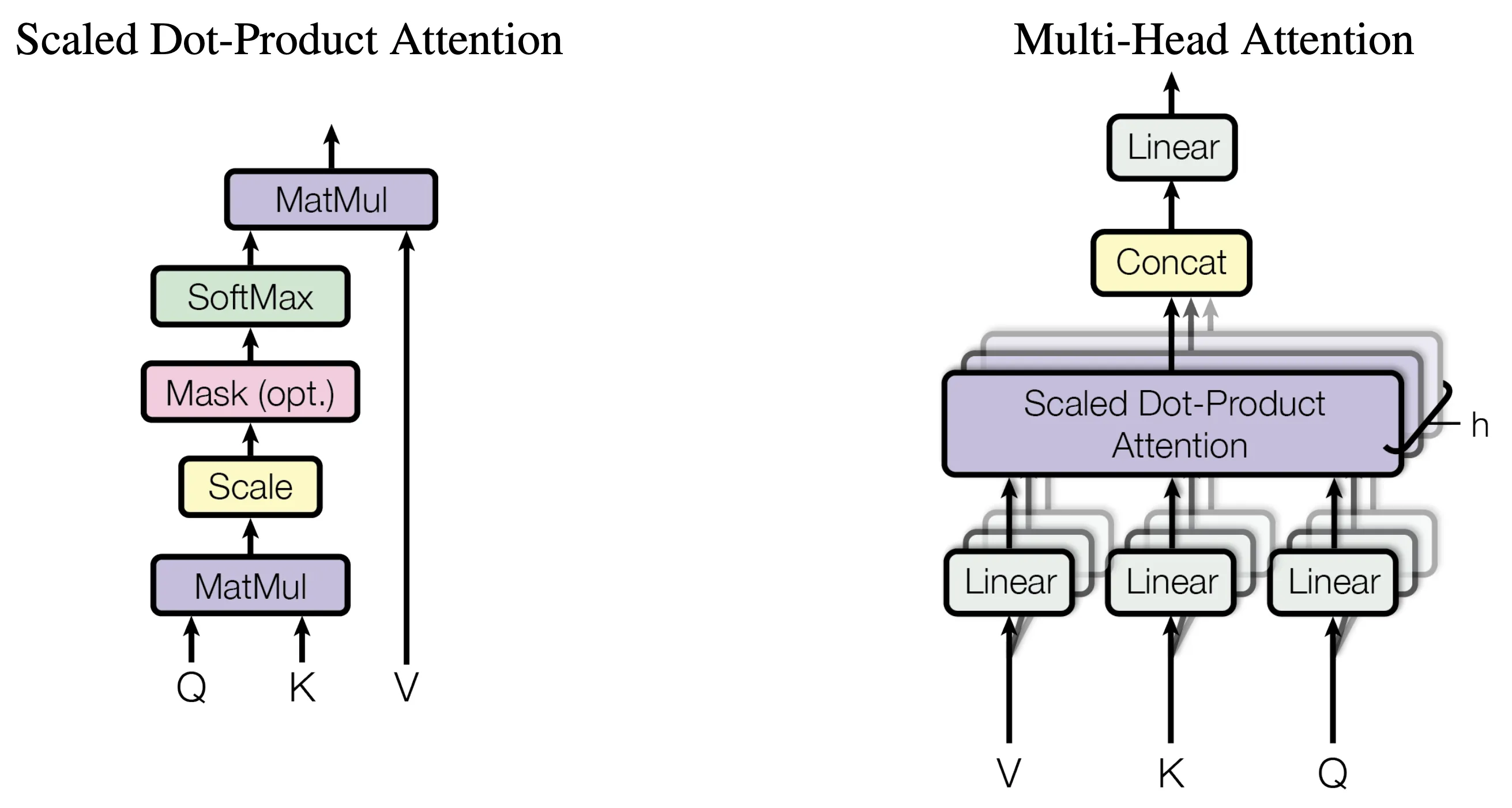
Untuk matematikanya, multi-head attention bisa dituliskan sebagai berikut:
MultiHead(Q, K, V) = Concat(head₁, head₂, ..., headₕ) W^O
Dimana setiap head didefinisikan sebagai:
headᵢ = Attention(QWᵢ^Q, KWᵢ^K, VWᵢ^V)
Dimana:
- Wᵢ^Q, Wᵢ^K, Wᵢ^V adalah weight matrix untuk masing-masing head
- W^O adalah weight matrix untuk menggabungkan semua head
- h adalah jumlah head (misalnya 8 atau 12)
Secara intuitif, setiap head itu seperti “sudut pandang” yang berbeda dalam melihat hubungan antar token.
Misalnya:
- satu head fokus ke hubungan antar kata (syntax)
- satu head fokus ke konteks kalimat
- satu head fokus ke dependency jarak jauh
Dengan adanya multi-head attention, model jadi tidak hanya melihat satu pola saja, tapi bisa menangkap banyak pola sekaligus dalam satu waktu.
Inilah yang membuat Transformer jauh lebih powerful dibanding arsitektur sebelumnya seperti RNN atau LSTM.
3. Feed Forward Network (FFN)
Setelah melalui attention, setiap token akan diproses kembali menggunakan feed forward network.
Berbeda dengan attention yang melihat hubungan antar token, FFN bekerja secara independen untuk setiap token (position-wise). Jadi setiap token diproses sendiri-sendiri dengan parameter yang sama.
Biasanya berupa dua layer neural network sederhana:
FFN(x) = max(0, xW1 + b1)W2 + b2
Dimana:
- W1, W2 adalah weight matrix
- b1, b2 adalah bias
- Fungsi max(0, x) adalah activation function ReLU
Secara lebih lengkap, prosesnya seperti ini:
- Input embedding dari token masuk ke layer pertama (linear transformation)
- Diberikan activation function (ReLU) untuk menambahkan non-linearitas
- Dilewatkan ke layer kedua untuk diproyeksikan kembali ke dimensi semula
Biasanya dimensi di layer pertama dibuat lebih besar (misalnya dari 512 → 2048), lalu dikembalikan lagi ke 512. Tujuannya agar model punya “ruang berpikir” yang lebih luas sebelum diringkas kembali.
Walaupun terlihat sederhana, bagian ini sangat penting karena:
- Menambahkan non-linearitas ke dalam model
- Membantu memperkaya representasi dari setiap token
- Melengkapi attention yang lebih fokus ke hubungan antar token
Jadi bisa dibilang:
- Attention → fokus ke hubungan antar token
- FFN → fokus memperdalam representasi tiap token
Kombinasi keduanya inilah yang membuat Transformer sangat powerful.
4. Residual Connection & Layer Normalization
Setiap sub-layer dalam Transformer dilengkapi dengan residual connection dan layer normalization.
Residual connection digunakan untuk menjaga agar informasi awal tidak hilang selama proses transformasi. Secara sederhana:
output = LayerNorm(x + Sublayer(x))
Hal ini juga membantu dalam mengatasi masalah vanishing gradient pada deep network.
Untuk bagian normalization, biasanya saya menggunakan Layer Normalization dengan rumus:
Dimana:
- μ (mu) adalah mean dari fitur
- σ² (sigma kuadrat) adalah variance
- ε (epsilon) adalah nilai kecil untuk menghindari pembagian dengan nol
- γ (gamma) dan β (beta) adalah parameter yang bisa dipelajari (learnable)
Secara intuitif, layer normalization ini bekerja dengan cara:
- Menormalkan distribusi data (mean ≈ 0, variance ≈ 1)
- Lalu memberikan fleksibilitas ke model lewat parameter γ dan β
Hal ini membuat:
- Training jadi lebih stabil
- Konvergensi lebih cepat
- Model lebih tahan terhadap perubahan distribusi data di setiap layer
Jadi bisa dibilang:
- Residual → menjaga aliran informasi & gradient
- LayerNorm → menjaga stabilitas distribusi data
Kombinasi keduanya ini sangat penting, terutama karena Transformer biasanya memiliki layer yang cukup dalam.
5. Masked Multi-Head Attention (Decoder Only)
Pada bagian decoder, terdapat mekanisme tambahan yaitu masked multi-head attention.
Masking digunakan agar model tidak “melihat masa depan”.
Artinya, ketika model sedang memprediksi token ke-n, model hanya boleh melihat token sebelum posisi tersebut, bukan token setelahnya.
Hal ini penting agar model benar-benar belajar untuk memprediksi secara autoregressive.
Secara matematis, masking ini biasanya direpresentasikan dalam bentuk matriks seperti berikut (causal mask):
Dimana:
- Nilai 0 berarti posisi tersebut boleh diperhatikan (visible)
- Nilai -\infty berarti posisi tersebut di-mask (tidak boleh diperhatikan)
Mask ini kemudian ditambahkan ke dalam perhitungan attention score sebelum softmax:
Attention(Q, K, V) = softmax((QK^T / √d_k) + M) V
Karena nilai -∞ akan menjadi 0 setelah softmax, maka token di masa depan otomatis tidak akan memiliki kontribusi dalam perhitungan attention.
Secara intuitif, ini seperti memaksa model untuk membaca kalimat dari kiri ke kanan, tanpa “mencontek” kata yang belum muncul.
Inilah yang membuat Transformer (khususnya decoder seperti GPT) bisa digunakan untuk:
- text generation
- language modeling
- autoregressive prediction
Penutup
Dari seluruh komponen tersebut, saya mulai menyadari bahwa Transformer bukan hanya sekadar arsitektur deep learning biasa, tetapi sebuah cara baru dalam memproses informasi.
Jika sebelumnya model dipaksa untuk memahami data secara berurutan, Transformer justru mengubah pendekatan tersebut menjadi paralel dan berbasis hubungan antar token.
Bagi saya pribadi, memahami Transformer memberikan perspektif baru bahwa dalam banyak kasus, memahami hubungan antar data bisa jauh lebih penting dibandingkan hanya melihat urutannya saja.
Dan mungkin, inilah salah satu alasan kenapa Transformer menjadi fondasi utama dari model-model modern seperti LLM saat ini.